Immutable Application Containers
Last month I was in Lugano presenting the last little study I conducted. The aim of this study was to check if results of an HPC workload depend on the underlying system.
TL;DR
If you don't like this thing called reading or you need more visual input:
This link jumps directly to the "meat" of the Talk (~28min into it).
Too Short;Wanna Read
In case you love reading: I wrote a (not peer reviewed) paper about it.
http://doc.qnib.org/HPCAC2015.pdf
 ]
]
Motivation
In a previous study I checked on the performance of MPI workloads within Docker containers and the outcome was promising. The overhead was negligible. I had an interview with Rich from insideHPC about it (Blog article).
But - I was wondering if the outcome of the computation is going to be stable among the different host systems. If that's not the case - there would be no need to look further into it...
Testbed
My testbed comprised of the hardware I got on hand or was available in the cloud. The systems I ran the containers on was pretty diverse in terms of user-land and kernel. Even though the user-land should not make much of a difference, since - you know - containers.
Hardware / Operating Systems
- Macbook Pro 3GHz, 16GB RAM (my workhorse)
- boot2docker (1.4), 3.16.7
- CoreOS 618, 3.19
- Workstation AMD Phenom II X4 (4core, 3.2 GHz)
- CentOS 6.6, 2.6.32
- 8 node cluster (2S XEONs, InfiniBand)
- CentOS 7.0alpha, 3.10.0
- Ubuntu12.04, 3.13.0 & 3.17.7
- Ubuntu14.10, 3.13.0 & 3.18.1
- AWS Instances (c3.xlarge w/ 4 CPUs, c4.4xlarge 2/ 16 CPUs)
- Ubuntu14.04, 3.13.0
- CoreOS 494, 3.17.2
- CoreOS 618, 3.19
Containers
All this hosts ran 3 variants of OpenFOAM application containers available on hub.docker.com:
- u1204of222: Ubuntu 12.04 & OpenFOAM 2.2.2 github branch u12.04_of222
- u1204of230: Ubuntu 12.04 & OpenFOAM 2.3.0 github branch u12.04_of230
- u1410of231: Ubuntu 14.10 & OpenFOAM 2.3.1 github branch u14.10_of231
Use-Case
The workload thrown at this setup was a beefed up version of cavity, a isothermal, incompressible flow with 3 solid walls and a lid moving with 1m/s.
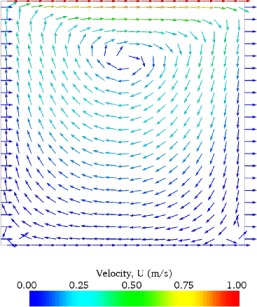
OK, I blew it up a 'bit' to increase the computational effort. From 20x20x1 cells to 1000x1000x1000 and I stretched the vertices by the factor 10. Furthermore I iterate 50 times with a 0.1ms steps.
To verify the end result each step calculates the averages cell pressure.
pAverage {
functionObjectLibs
("libutilityFunctionObjects.so");
type coded;
redirectType average;
outputControl timeStep;
code
#{
const volScalarField& p =
mesh().lookupObject<volScalarField>("p");
Info<<"p avg:" << average(p) << endl;
#};
This spits the pressure out after each iteration:
*snip*
p avg:average(p) [0 2 -2 0 0 0 0] 0.521992
Time = 0.0004
Courant Number mean: 0.000471644 max: 0.080226
*snip*
ExecutionTime = 25.99 s ClockTime = 134 s
p avg:average(p) [0 2 -2 0 0 0 0] 0.349272
Time = 0.0005
Result
After I collected all the logs from all runs, I fired up an ugly bash script to compute the sums of the average pressure:
for lfile in $(find . -name log);do
prefix=$(echo $lfile |awk -F/ '{print $2}')
str=$(grep "^p " $lfile |awk '{print $10}'|xargs)
sum=$(echo $str |sed -e 's/ /+/g'|bc)
echo "${sum} | ${prefix}"
done
8.6402816 | b2d_u12_of222
8.6402463 | b2d_u12_of230
8.6402816 | c3.xlarge-core494_docker_u12-of222
8.6402463 | c3.xlarge-core494_docker_u12-of230
8.6402816 | c3.xlarge-u14_docker_u12-of222
8.6402463 | c3.xlarge-u14_docker_u12-of230
8.6402816 | c4.4xlarge-u14_docker_u12-of222
8.6402463 | c4.4xlarge-u14_docker_u12-of230
8.6402463 | c4.4xlarge-u14_docker_u14-of231
*snip*
Turns out that the result is equal (up to my measurement approach) within minor releases among all test runs.
The runtime varied a lot though (in minutes, 16 way parallel)...
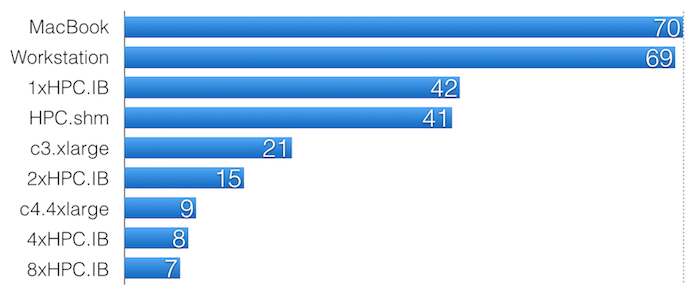
Conclusion
After a couple of month of result-settlement I am getting used to the outcome. The user-land of the host system has no effect at all, since the container talks directly to the host kernel. The containers user-land uses system calls to interact with the underlying kernel and since this is quite stable the result should be stable as well.
Future work
What I still surprised about is how stable the sys-call interface really is. The cavity case used iterates towards a deterministic results, the more computation is done the more precise the result - but no surprises are expectable. I should conduct the study a second time with a Karman Vortex Street use-case.
The flow over this rounded object is chaotic and reacts on random events. If the result is still the same among different host systems... That would proof the encapsulation...
At the end of the day I should take a couple of days off and educate myself on the internals of the Linux System Interface.