QNIBTerminal: Quick Start using bash
Yesterday I pimped the way to build the cluster; now it is time to start the beast. For now it is a simple bash function; there must be a smarter way... fabfile, I heard... :)
The cluster looks like this...

The QNIBTerminal repository holds a bashrc file, which porvides a function to start all the blue parts.
$ start_qnibterminal
#### Start dns EC: 0 ID: 460b9b8ca060631e399ce5d79969a431f45be2087650a08d53f521306351b799
#### Start elk EC: 0 ID: fbca81101d25cb4cd71a4a6cd3561e4e4229d0609a29c8ae7c940c180e4df3dd
#### Start carbon EC: 0 ID: d43b858197d46b1f57fcbcfd136c4e431f7f033261593e7a3bd8b7d21faa541a
#### Start graphite-web EC: 0 ID: ffe964bc6a30b786c4e78543c9570ac86da40c50ea56731475262a340ae26a0b
#### Start graphite-api EC: 0 ID: 02b858236a4333a9dd04342966198b2f1a69a09d78ba13ff3e4c001b45a3169a
#### Start grafana EC: 0 ID: cd3de374874b0e73643fca4ce0343ad5fff8d0a3294a27e18b0d6461efd0ba47
#### Start haproxy EC: 0 ID: fa017dad888b468b517475a75d32b5d6cf637e94195389da4d08e186cc69023c
#### Start slurmctld EC: 0 ID: 039601b587be8928c70d1c5409c918359fa674b710f7b0781c7052658707c2f7
Websites
HAPROXY servers the different web-sites under the IP of the docker host.
Kibana is available under /kibana/:
The grafana dashboard under /grafana/:
Compute
The first compute node is started attached, as to submit jobs.
$ start_comp compute0 1
bash-4.2# su -
[root@compute0 ~]# supervisor_daemonize.sh
# supervisorctl status
confd_update_slurm RUNNING pid 45, uptime 0:00:05
diamond RUNNING pid 42, uptime 0:00:05
munge RUNNING pid 44, uptime 0:00:05
setup EXITED Jun 10 08:32 PM
slurmd RUNNING pid 105, uptime 0:00:03
sshd RUNNING pid 41, uptime 0:00:05
syslog-ng RUNNING pid 43, uptime 0:00:05
[root@compute0 ~]# sleep 15; sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
docker* up infinite 1 idle compute0
[root@compute0 ~]# srun -N1 hostname
compute0
[root@compute0 ~]#
Other nodes are started detached.
$ for comp in compute{1..3};do start_comp ${comp}; sleep 2;done
c67f00db03c7af8069ec420ea0c15c86085fb09a81f409104e8576978df69697
f6e2c9d06258ad097378e0d997128b4e3e81f16ea0dc01b841a1d9c6beed8764
f6e2c9d06258ad097378e0d997128b4e3e81f16ea0dc01b841a1d9c6beed8764
e67023a3fccb745b15034331dacc331f8d4bffdb3c01393d6446794a80b9a74c
The compute0 node should reflect this change, by adapting the sinfo output.
[root@compute0 ~]# sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
docker* up infinite 4 idle compute[0-3]
And here we go. Now MPI jobs could be submitted:
[root@compute0 ~]# source /etc/profile
[root@compute0 ~]# module load mpi
[root@compute0 ~]# sbatch -N4 /usr/local/bin/gemm.sh
Submitted batch job 3
[root@compute0 ~]# sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
docker* up infinite 4 alloc compute[0-3]
[root@compute0 ~]#
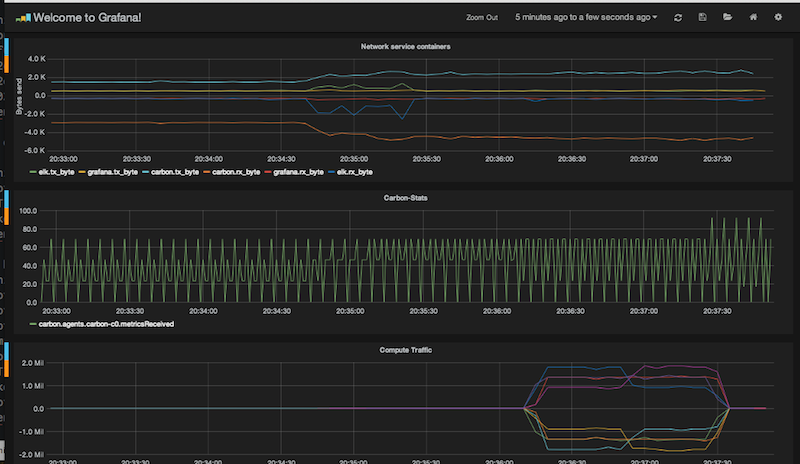
And by starting 12 more nodes, I push my little 4core machine at home to the limit... :)
[root@compute0 ~]# sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
docker* up infinite 16 idle compute[0-15]
[root@compute0 ~]# sbatch -N16 /usr/local/bin/gemm.sh
Submitted batch job 4
[root@compute0 ~]# sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
docker* up infinite 16 alloc compute[0-15]
[root@compute0 ~]#
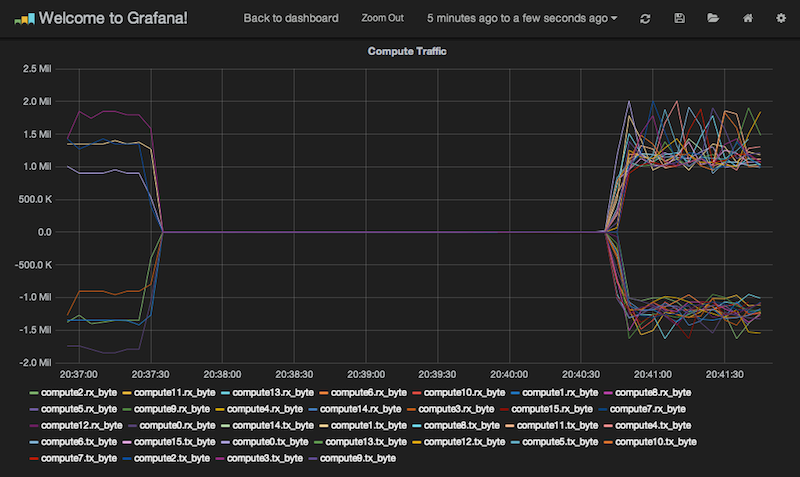
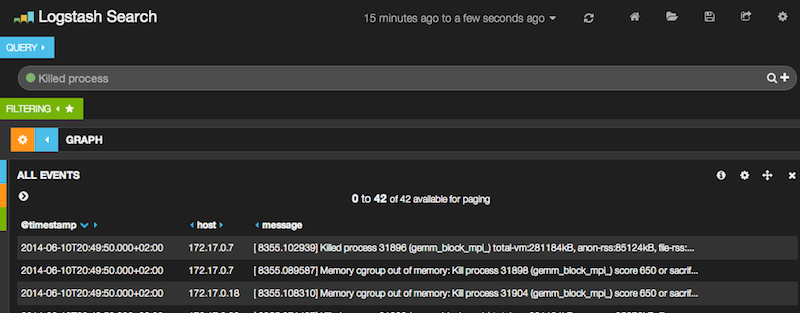
A job started with an matrix size of 2^16.
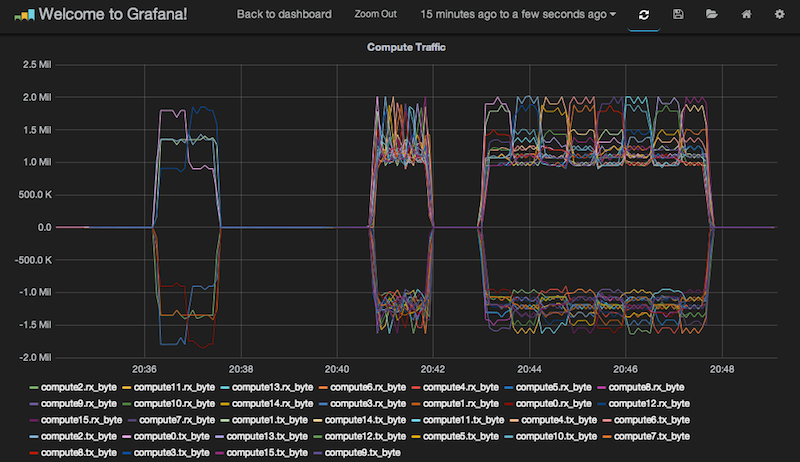
A job with 2^17 is killed...